library(readr)
library(ggplot2)
library(tidyverse)
library(readxl)
library(lubridate)
knitr::opts_chunk$set(echo = TRUE, warning=FALSE, message=FALSE)Challenge 6
challenge_6
fed_rate
debt
Visualizing Time and Relationships
Challenge Overview
The dataset used is debt. It contains 8 variables and 74 observations. The variables contain information about different types of debt such as mortgage and student loans. This information is presented quarter-wise from 2003 until 2021. However, the data for 2021 is only of 2 quarters.
#debt<- read_excel("_data/debt_in_trillions.xlsx",col_names=c("year_quart","mortgage","he_revolve","auto_loan","cred_card","stud_loan","other","total"),skip=1)
debt<- read_excel("_data/debt_in_trillions.xlsx")
dim(debt)[1] 74 8print(summarytools::dfSummary(debt,
varnumbers = FALSE,
plain.ascii = FALSE,
style = "grid",
graph.magnif = 0.70,
valid.col = FALSE),
method = 'render',
table.classes = 'table-condensed')Data Frame Summary
debt
Dimensions: 74 x 8Duplicates: 0
| Variable | Stats / Values | Freqs (% of Valid) | Graph | Missing | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year and Quarter [character] |
|
|
 |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mortgage [numeric] |
|
74 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| HE Revolving [numeric] |
|
73 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Auto Loan [numeric] |
|
71 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Credit Card [numeric] |
|
69 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Student Loan [numeric] |
|
73 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Other [numeric] |
|
70 distinct values |  |
0 (0.0%) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Total [numeric] |
|
74 distinct values |  |
0 (0.0%) |
Generated by summarytools 1.0.1 (R version 4.2.1)
2022-08-23
The data is not already tidy, the various types of debt need to be pivoted into rows in order to be analysed easily. Moreover, the year and quarter column is of character type and needs to be converted into a date format.
#number of rows=74
#number of columns=8
#number of cases=6
#expected rows
rows=74*6
print("Expected number of rows:")[1] "Expected number of rows:"rows[1] 444# expected columns
col=(8-6)+2
print("Expected number of columns:")[1] "Expected number of columns:"col[1] 4debt<-pivot_longer(debt, 2:7, names_to = "Type_Debt", values_to = "Amount")
dim(debt)[1] 444 4debt<-debt%>%mutate(date = parse_date_time(`Year and Quarter`,
orders="yq"))%>%
select(-'Year and Quarter')
debt<-debt%>%select(date,Type_Debt,Amount,everything())
debtThe visualisation below depicts that overall, across the years, the debt has risen. However, this was not a linear rise as the debt declined from around 2009 to around 2013, before it started rising again. Since the debt data is continuous, I represented it in the form of a scatterplot.
ggplot(debt, aes(date,`Total`)) +
geom_point() +
labs(title = "Total Debt across the Years")+ ylim(7,15)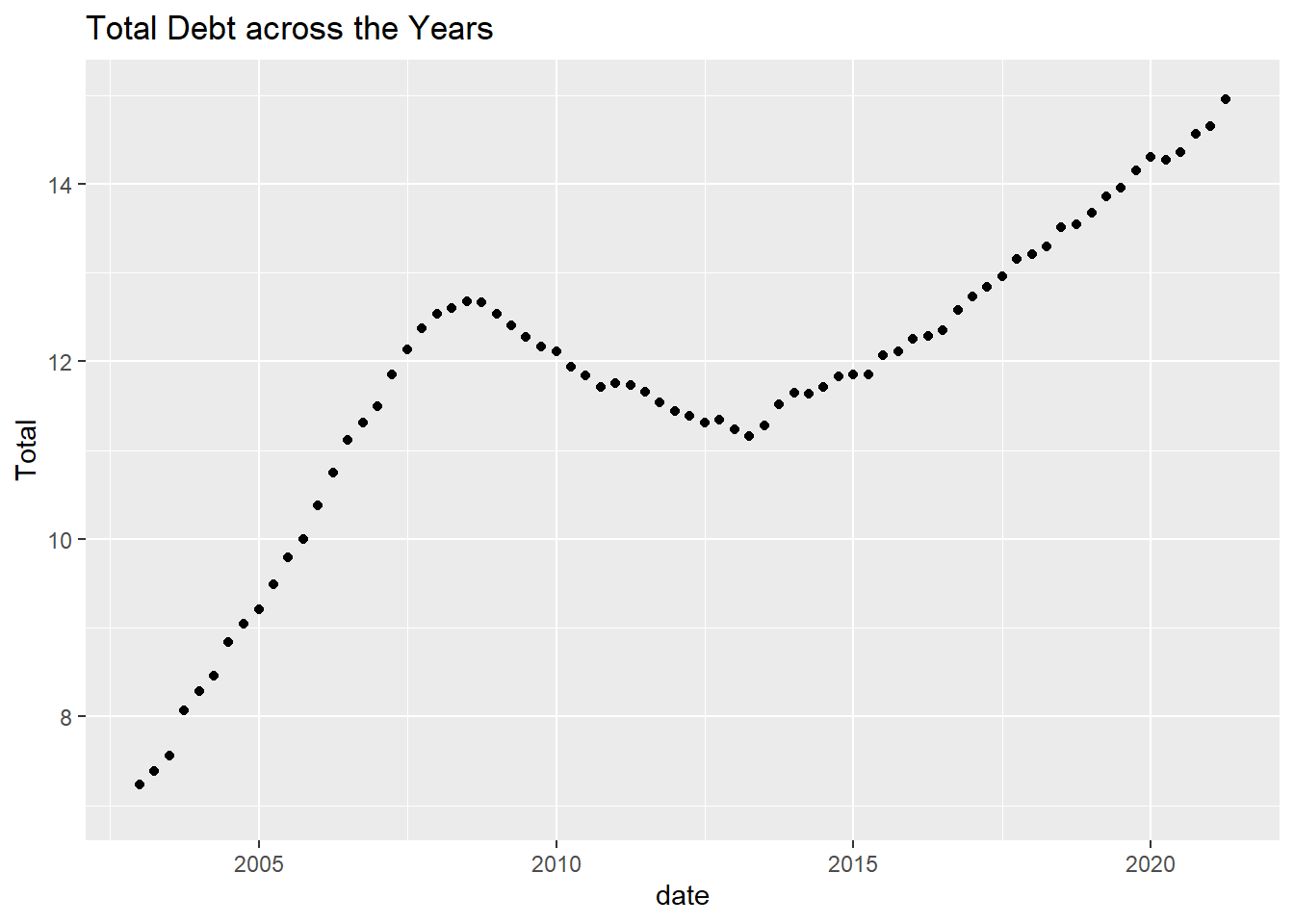
From the pie chart below, it is evident that majority of the debt comes from mortgage, followed by car loans and student loans which are similar in size. This corresponds closely to the common needs of housing, education and transportation. A pie chart was used because it could depict the different kinds of debt and what proportion of these kinds contribute to the total debt.
ggplot(debt, aes(x="", y=Amount, fill=Type_Debt)) +
geom_bar(stat="identity", width=1) +
coord_polar("y", start=0)+
labs(title = "Types of Debt")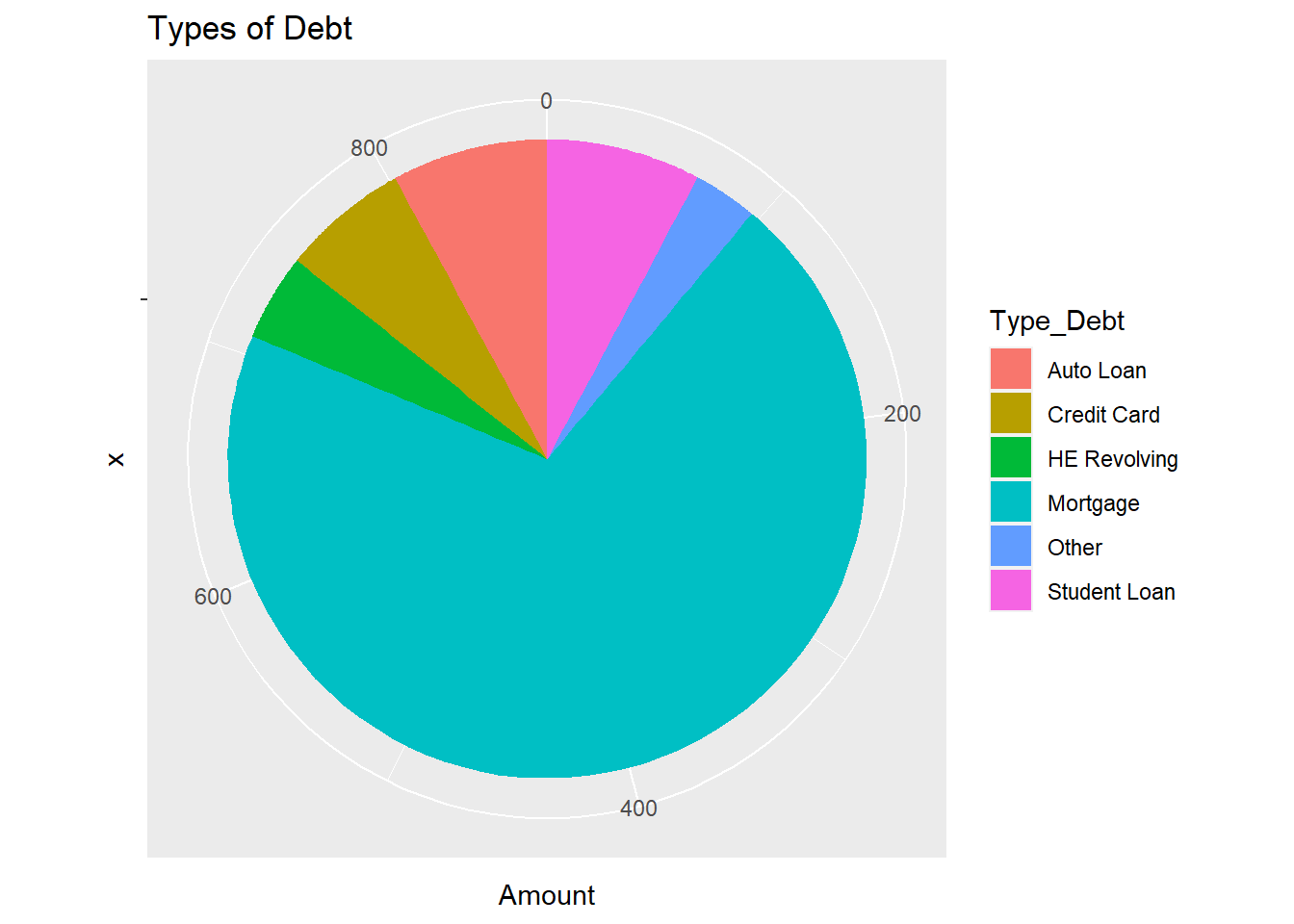
Federal Funds Rate
Description of data
The dataset has the target interest rates as well as details of the GDP, unemployment rate and inflation rate between 1954-2017. It has 10 variables and 904 observations. A few of the variables such as the Federal Funds Upper Target, Federal Funds Lower Target and Real GDP, have more than half of the total observations missing.
FundsRate <- read_csv("_data/FedFundsRate.csv")
dim(FundsRate)[1] 904 10print(summarytools::dfSummary(FundsRate,
varnumbers = FALSE,
plain.ascii = FALSE,
style = "grid",
graph.magnif = 0.70,
valid.col = FALSE),
method = 'render',
table.classes = 'table-condensed')Data Frame Summary
FundsRate
Dimensions: 904 x 10Duplicates: 0
| Variable | Stats / Values | Freqs (% of Valid) | Graph | Missing | ||||
|---|---|---|---|---|---|---|---|---|
| Year [numeric] |
|
64 distinct values |  |
0 (0.0%) | ||||
| Month [numeric] |
|
12 distinct values |  |
0 (0.0%) | ||||
| Day [numeric] |
|
29 distinct values |  |
0 (0.0%) | ||||
| Federal Funds Target Rate [numeric] |
|
63 distinct values |  |
442 (48.9%) | ||||
| Federal Funds Upper Target [numeric] |
|
4 distinct values |  |
801 (88.6%) | ||||
| Federal Funds Lower Target [numeric] |
|
4 distinct values | |
801 (88.6%) | ||||
| Effective Federal Funds Rate [numeric] |
|
466 distinct values |  |
152 (16.8%) | ||||
| Real GDP (Percent Change) [numeric] |
|
113 distinct values |  |
654 (72.3%) | ||||
| Unemployment Rate [numeric] |
|
71 distinct values |  |
152 (16.8%) | ||||
| Inflation Rate [numeric] |
|
106 distinct values |  |
194 (21.5%) |
Generated by summarytools 1.0.1 (R version 4.2.1)
2022-08-23
Tidy Data
The data is not already tidy, some of the columns need to be pivoted in order for the final dataset to have federal funds rates and economic indicators as specific columns. Moreover, the date is spread across three columns and needs to be consolidated into one column.
The calculation for the number of rows that will be present after pivoting was done in 2 steps as 2 different pivots were used.First, the number of rows that would be present after 1 pivot was calculated and then this value was multiplied by the number of columns that would be pivoted during the second run.
#number of rows=904
#number of columns=8
#number of cases=7
#expected rows
rows=(904*4)
rows=rows*3
print("Expected number of rows:")[1] "Expected number of rows:"rows[1] 10848# expected columns
col=(8-4-3)+4
print("Expected number of columns:")[1] "Expected number of columns:"col[1] 5FundsRate <- FundsRate%>%mutate(Date = str_c(Year, Month, Day, sep="-"),
Date = ymd(Date))
FundsRate=subset(FundsRate,select=-c(1,2,3))
FundsRate<-FundsRate%>%select(Date,everything())
FundsRate<-pivot_longer(FundsRate, 2:5, names_to = "TargetRates", values_to = "TRValue")
FundsRate<-pivot_longer(FundsRate, 2:4, names_to = "EconomicIndicators", values_to = "EIValue")
dim(FundsRate)[1] 10848 5Time Dependent Visualisation
The Effective Federal Funds Rate first rose and then with fluctuations in between whereas the Federal Funds Target Rate has continuously declined over the years. There does not seem to be much change in the Upper and Lower Targets, however, this issue could be because the scale used may not be allowing the changes to be seen distinctly.
While unemployment rates and inflation rates seem to have a similar trend of fluctuating(although the rise and fall does not necessarily happen at the same time) the Real GDP has no discernible pattern.
ggplot(FundsRate, aes(Date,`TRValue`)) +
geom_point() +
labs(title = "Target Rates across the Years")+facet_wrap(vars(TargetRates))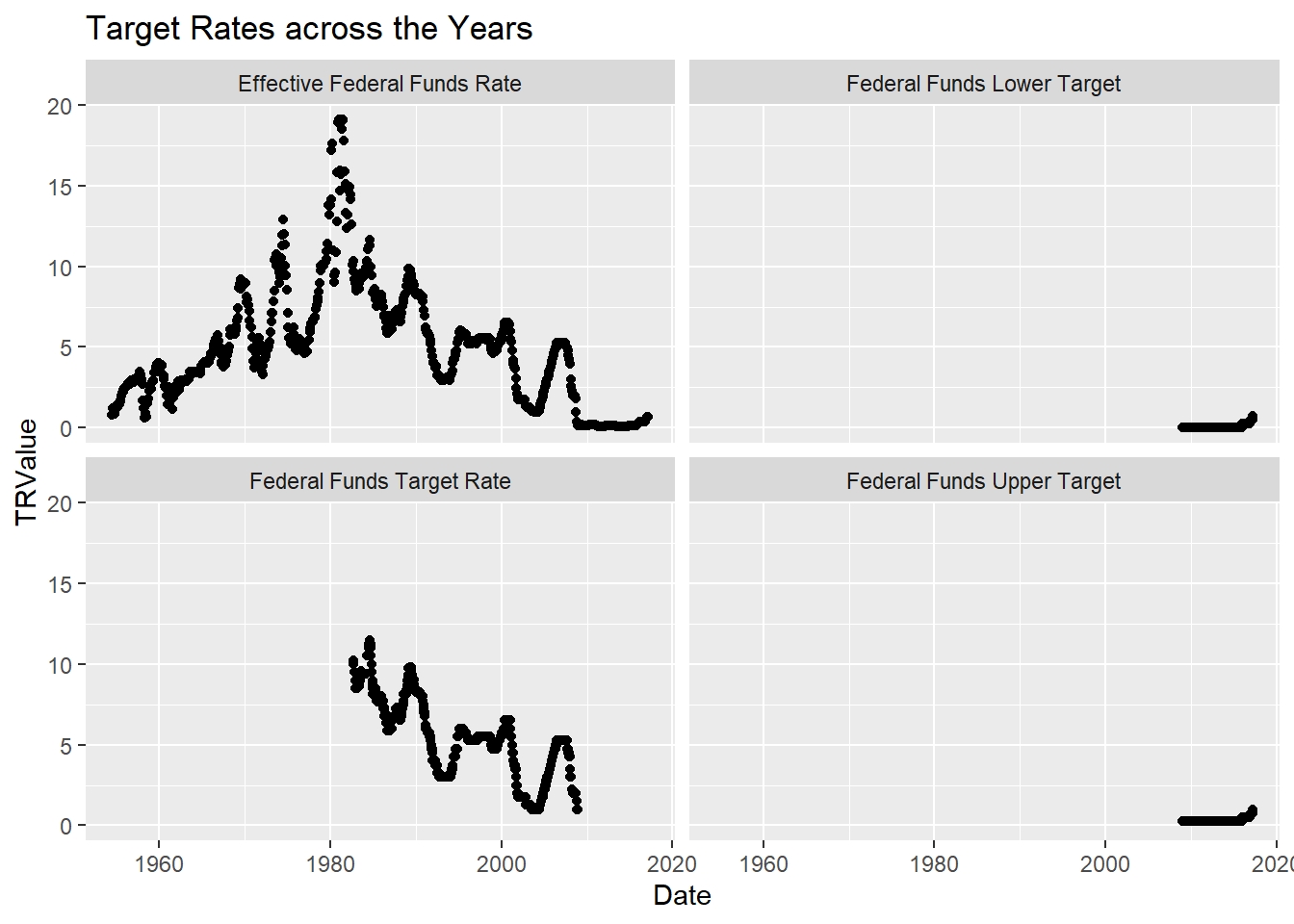
ggplot(FundsRate, aes(Date,`EIValue`)) +
geom_point() +
labs(title = "Economic Indicators across the Years")+facet_wrap(vars(EconomicIndicators))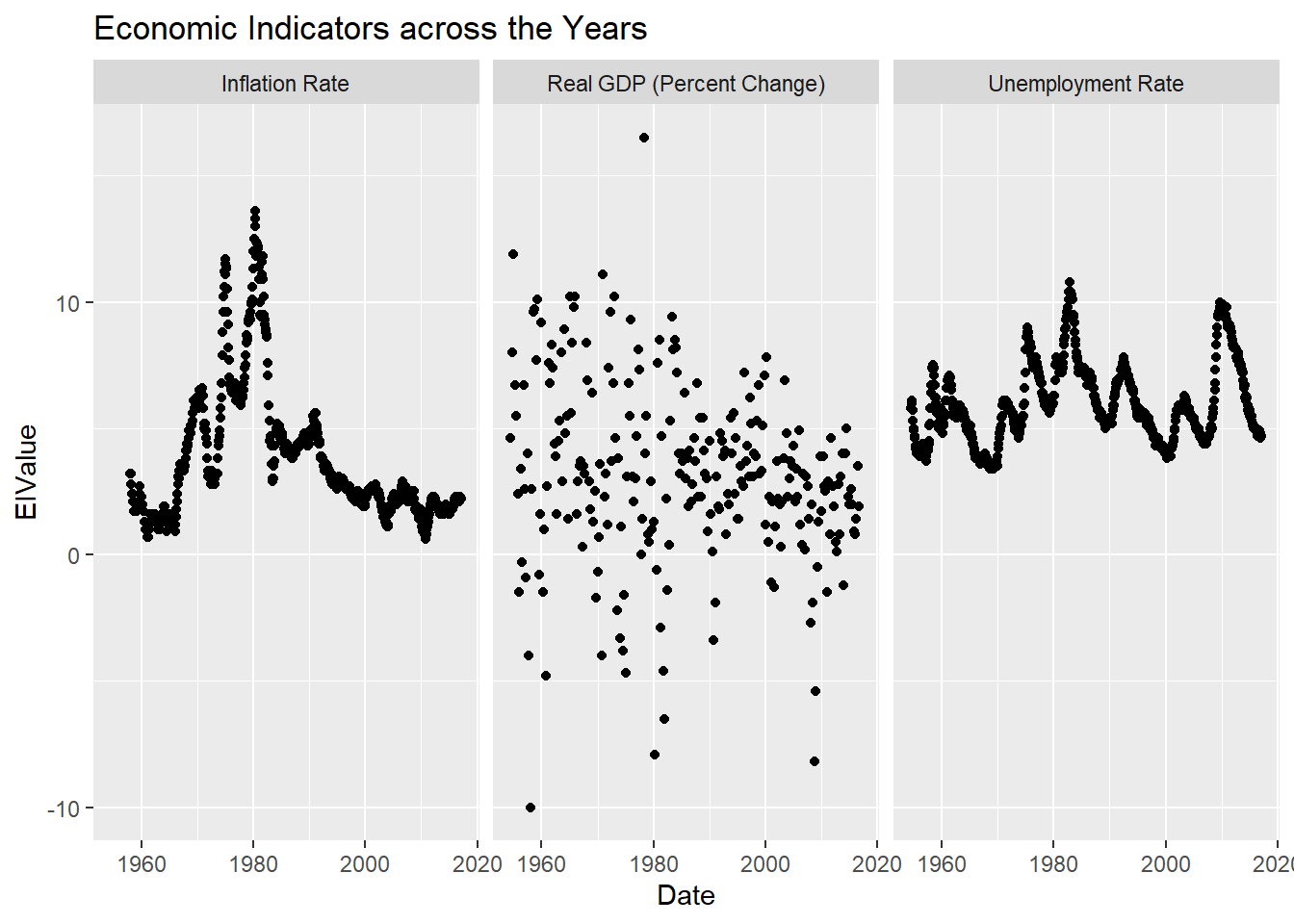
Visualising Part-Whole Relationships
I plotted a stacked bar chart since there were two categorical variables and one continuous variable. However, this does not seem to depict anything useful as the proportion of the target rates in all the bars look similar.
Plotting a pie chart or doughnut chart would not be useful in this case as the rates/ economic indicators are not representative of a total larger value.
ggplot(FundsRate, aes(fill=TargetRates, y=EIValue, x=EconomicIndicators)) +
geom_bar(position="stack", stat="identity") 
:::